Want to know Examcollection DP-200 Exam practice test features? Want to lear more about Microsoft Implementing an Azure Data Solution certification experience? Study Precise Microsoft DP-200 answers to Latest DP-200 questions at Examcollection. Gat a success with an absolute guarantee to pass Microsoft DP-200 (Implementing an Azure Data Solution) test on your first attempt.
Also have DP-200 free dumps questions for you:
NEW QUESTION 1
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some questions sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You need to implement diagnostic logging for Data Warehouse monitoring. Which log should you use?
- A. RequestSteps
- B. DmsWorkers
- C. SqlRequests
- D. ExecRequests
Answer: C
Explanation:
Scenario:
The Azure SQL Data Warehouse cache must be monitored when the database is being used.
References:
https://docs.microsoft.com/en-us/sql/relational-databases/system-dynamic-management-views/sys-dm-pdw-sql-r
NEW QUESTION 2
You need to ensure phone-based polling data upload reliability requirements are met. How should you configure monitoring? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.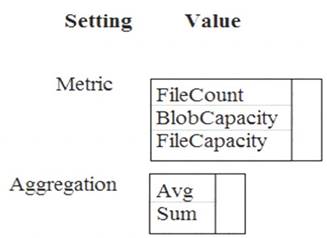
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: FileCapacity
FileCapacity is the amount of storage used by the storage account’s File service in bytes. Box 2: Avg
The aggregation type of the FileCapacity metric is Avg.
Scenario:
All services and processes must be resilient to a regional Azure outage.
All Azure services must be monitored by using Azure Monitor. On-premises SQL Server performance must be monitored.
References:
https://docs.microsoft.com/en-us/azure/azure-monitor/platform/metrics-supported
NEW QUESTION 3
You implement an event processing solution using Microsoft Azure Stream Analytics. The solution must meet the following requirements:
•Ingest data from Blob storage
• Analyze data in real time
•Store processed data in Azure Cosmos DB
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 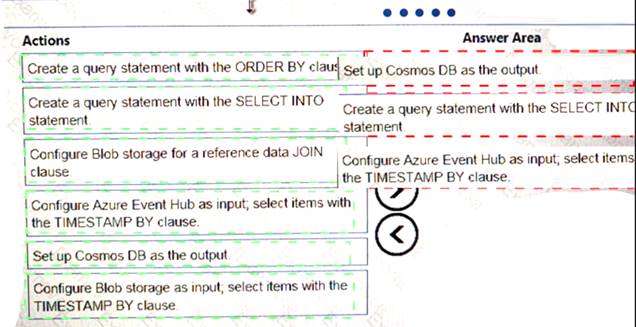
NEW QUESTION 4
Your company plans to create an event processing engine to handle streaming data from Twitter. The data engineering team uses Azure Event Hubs to ingest the streaming data.
You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs.
Which three actions should you recommend be performed in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.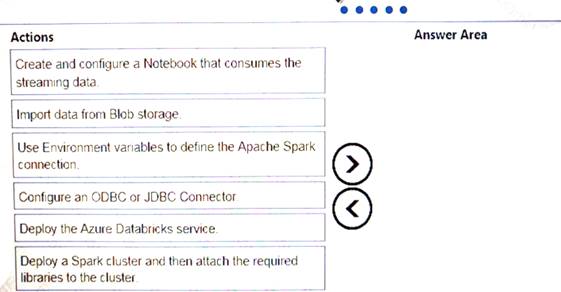
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 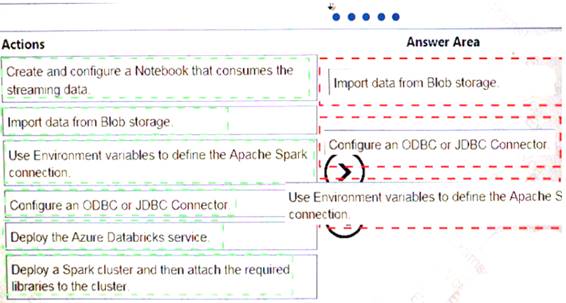
NEW QUESTION 5
You develop data engineering solutions for a company.
You must integrate the company’s on-premises Microsoft SQL Server data with Microsoft Azure SQL Database. Data must be transformed incrementally.
You need to implement the data integration solution.
Which tool should you use to configure a pipeline to copy data?
- A. Use the Copy Data tool with Blob storage linked service as the source
- B. Use Azure PowerShell with SQL Server linked service as a source
- C. Use Azure Data Factory UI with Blob storage linked service as a source
- D. Use the .NET Data Factory API with Blob storage linked service as the source
Answer: C
Explanation:
The Integration Runtime is a customer managed data integration infrastructure used by Azure Data Factory to provide data integration capabilities across different network environments.
A linked service defines the information needed for Azure Data Factory to connect to a data resource. We have three resources in this scenario for which linked services are needed: On-premises SQL Server
On-premises SQL Server  Azure Blob Storage Azure SQL database
Azure Blob Storage Azure SQL database
Note: Azure Data Factory is a fully managed cloud-based data integration service that orchestrates and automates the movement and transformation of data. The key concept in the ADF model is pipeline. A pipeline is a logical grouping of Activities, each of which defines the actions to perform on the data contained in Datasets. Linked services are used to define the information needed for Data Factory to connect to the data resources.
References:
https://docs.microsoft.com/en-us/azure/machine-learning/team-data-science-process/move-sql-azure-adf
NEW QUESTION 6
A company builds an application to allow developers to share and compare code. The conversations, code snippets, and links shared by people in the application are stored in a Microsoft Azure SQL Database instance. The application allows for searches of historical conversations and code snippets.
When users share code snippets, the code snippet is compared against previously share code snippets by using a combination of Transact-SQL functions including SUBSTRING, FIRST_VALUE, and SQRT. If a match is found, a link to the match is added to the conversation.
Customers report the following issues: Delays occur during live conversations A delay occurs before matching links appear after code snippets are added to conversations
Delays occur during live conversations A delay occurs before matching links appear after code snippets are added to conversations
You need to resolve the performance issues.
Which technologies should you use? To answer, drag the appropriate technologies to the correct issues. Each technology may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.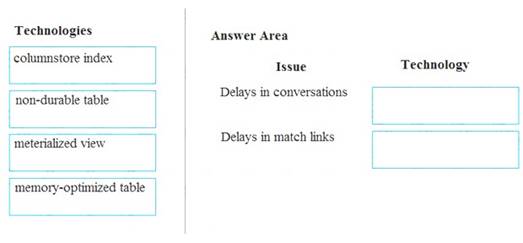
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Box 1: memory-optimized table
In-Memory OLTP can provide great performance benefits for transaction processing, data ingestion, and transient data scenarios.
Box 2: materialized view
To support efficient querying, a common solution is to generate, in advance, a view that materializes the data in a format suited to the required results set. The Materialized View pattern describes generating prepopulated views of data in environments where the source data isn't in a suitable format for querying, where generating a suitable query is difficult, or where query performance is poor due to the nature of the data or the data store.
These materialized views, which only contain data required by a query, allow applications to quickly obtain the information they need. In addition to joining tables or combining data entities, materialized views can include the current values of calculated columns or data items, the results of combining values or executing transformations on the data items, and values specified as part of the query. A materialized view can even be optimized for just a single query.
References:
https://docs.microsoft.com/en-us/azure/architecture/patterns/materialized-view
NEW QUESTION 7
You develop data engineering solutions for a company.
A project requires an in-memory batch data processing solution.
You need to provision an HDInsight cluster for batch processing of data on Microsoft Azure.
How should you complete the PowerShell segment? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.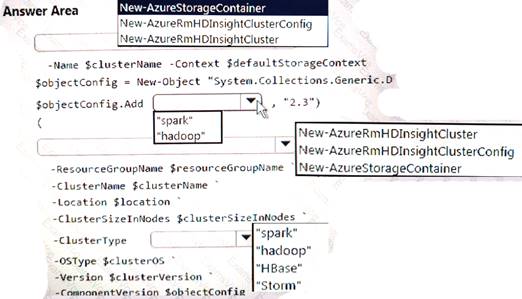
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 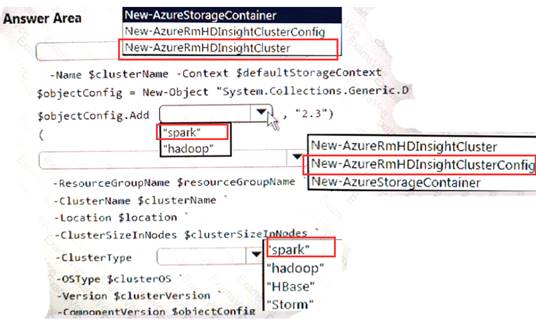
NEW QUESTION 8
Your company uses Microsoft Azure SQL Database configure with Elastic pool. You use Elastic Database jobs to run queries across all databases in the pod.
You need to analyze, troubleshoot, and report on components responsible for running Elastic Database jobs. You need to determine the component responsible for running job service tasks.
Which components should you use for each Elastic pool job services task? To answer, drag the appropriate component to the correct task. Each component may be used once, more than once, or not at all. You may
need to drag the split bar between panes or scroll to view content. NOTE: Each correct selection is worth one point.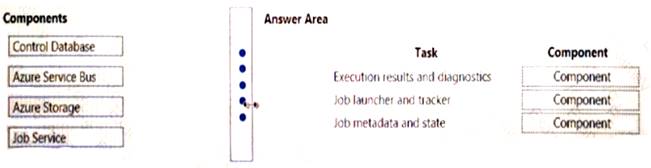
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
NEW QUESTION 9
A company plans to analyze a continuous flow of data from a social media platform by using Microsoft Azure Stream Analytics. The incoming data is formatted as one record per row.
You need to create the input stream.
How should you complete the REST API segment? To answer, select the appropriate configuration in the answer area.
NOTE: Each correct selection is worth one point.

- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 
NEW QUESTION 10
You need to ensure that phone-based poling data can be analyzed in the PollingData database. How should you configure Azure Data Factory?
- A. Use a tumbling schedule trigger
- B. Use an event-based trigger
- C. Use a schedule trigger
- D. Use manual execution
Answer: C
Explanation:
When creating a schedule trigger, you specify a schedule (start date, recurrence, end date etc.) for the trigger, and associate with a Data Factory pipeline.
Scenario:
All data migration processes must use Azure Data Factory
All data migrations must run automatically during non-business hours References:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-create-schedule-trigger
NEW QUESTION 11
A company plans to develop solutions to perform batch processing of multiple sets of geospatial data. You need to implement the solutions.
Which Azure services should you use? To answer, select the appropriate configuration tit the answer area. NOTE: Each correct selection is worth one point.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 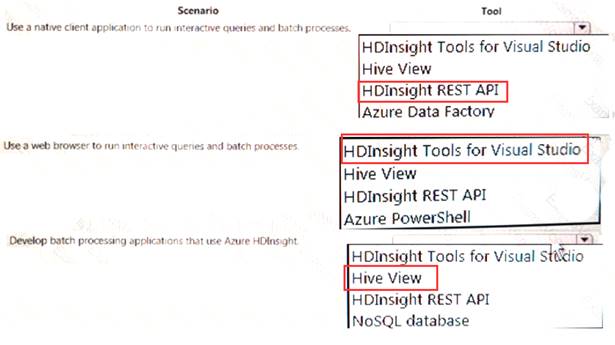
NEW QUESTION 12
You develop data engineering solutions for a company. The company has on-premises Microsoft SQL Server databases at multiple locations.
The company must integrate data with Microsoft Power BI and Microsoft Azure Logic Apps. The solution must avoid single points of failure during connection and transfer to the cloud. The solution must also minimize latency.
You need to secure the transfer of data between on-premises databases and Microsoft Azure.
What should you do?
- A. Install a standalone on-premises Azure data gateway at each location
- B. Install an on-premises data gateway in personal mode at each location
- C. Install an Azure on-premises data gateway at the primary location
- D. Install an Azure on-premises data gateway as a cluster at each location
Answer: D
Explanation:
You can create high availability clusters of On-premises data gateway installations, to ensure your organization can access on-premises data resources used in Power BI reports and dashboards. Such clusters allow gateway administrators to group gateways to avoid single points of failure in accessing on-premises data resources. The Power BI service always uses the primary gateway in the cluster, unless it’s not available. In that case, the service switches to the next gateway in the cluster, and so on.
References:
https://docs.microsoft.com/en-us/power-bi/service-gateway-high-availability-clusters
NEW QUESTION 13
The data engineering team manages Azure HDInsight clusters. The team spends a large amount of time creating and destroying clusters daily because most of the data pipeline process runs in minutes.
You need to implement a solution that deploys multiple HDInsight clusters with minimal effort. What should you implement?
- A. Azure Databricks
- B. Azure Traffic Manager
- C. Azure Resource Manager templates
- D. Ambari web user interface
Answer: C
Explanation:
A Resource Manager template makes it easy to create the following resources for your application in a single, coordinated operation: HDInsight clusters and their dependent resources (such as the default storage account). Other resources (such as Azure SQL Database to use Apache Sqoop).
In the template, you define the resources that are needed for the application. You also specify deployment parameters to input values for different environments. The template consists of JSON and expressions that you use to construct values for your deployment.
References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-create-linux-clusters-arm-templates
NEW QUESTION 14
A company uses Microsoft Azure SQL Database to store sensitive company data. You encrypt the data and only allow access to specified users from specified locations.
You must monitor data usage, and data copied from the system to prevent data leakage.
You need to configure Azure SQL Database to email a specific user when data leakage occurs.
Which three actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.
- A. Mastered
- B. Not Mastered
Answer: A
Explanation: 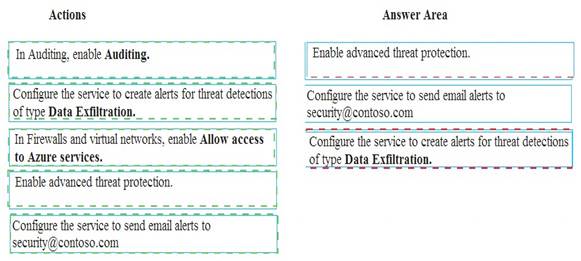
NEW QUESTION 15
A company manages several on-premises Microsoft SQL Server databases.
You need to migrate the databases to Microsoft Azure by using the backup process of Microsoft SQL Server. Which data technology should you use?
- A. Azure SQL Database Managed Instance
- B. Azure SQL Data Warehouse
- C. Azure Cosmos DB
- D. Azure SQL Database single database
Answer: D
NEW QUESTION 16
A company is deploying a service-based data environment. You are developing a solution to process this data. The solution must meet the following requirements: Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service Use an Azure Data Lake Storage account to store processed data Allow users to download processed data
You need to recommend technologies for the solution.
Which technologies should you use? To answer, select the appropriate options in the answer area.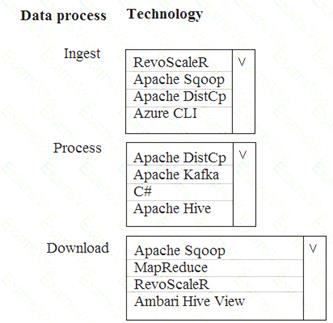
- A. Mastered
- B. Not Mastered
Answer: A
Explanation:
Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Azure HDInsight is a cloud distribution of the Hadoop components from the Hortonworks Data Platform (HDP).
NEW QUESTION 17
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop data engineering solutions for a company.
A project requires the deployment of resources to Microsoft Azure for batch data processing on Azure
HDInsight. Batch processing will run daily and must: Scale to minimize costs
Be monitored for cluster performance
You need to recommend a tool that will monitor clusters and provide information to suggest how to scale. Solution: Monitor cluster load using the Ambari Web UI.
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
Ambari Web UI does not provide information to suggest how to scale.
Instead monitor clusters by using Azure Log Analytics and HDInsight cluster management solutions. References:
https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-oms-log-analytics-tutorial https://docs.microsoft.com/en-us/azure/hdinsight/hdinsight-hadoop-manage-ambari
NEW QUESTION 18
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account. You need to toad the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data
Warehouse.
Solution:
1. Create an external data source pointing to the Azure storage account
2. Create an external file format and external table using the external data source
3. Load the data using the INSERT…SELECT statement
Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
You load the data using the CREATE TABLE AS SELECT statement. References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
NEW QUESTION 19
Each day, company plans to store hundreds of files in Azure Blob Storage and Azure Data Lake Storage. The company uses the parquet format.
You must develop a pipeline that meets the following requirements:  Process data every six hours Offer interactive data analysis capabilities Offer the ability to process data using solid-state drive (SSD) caching Use Directed Acyclic Graph(DAG) processing mechanisms Provide support for REST API calls to monitor processes
Process data every six hours Offer interactive data analysis capabilities Offer the ability to process data using solid-state drive (SSD) caching Use Directed Acyclic Graph(DAG) processing mechanisms Provide support for REST API calls to monitor processes  Provide native support for Python Integrate with Microsoft Power BI
Provide native support for Python Integrate with Microsoft Power BI
You need to select the appropriate data technology to implement the pipeline. Which data technology should you implement?
- A. Azure SQL Data Warehouse
- B. HDInsight Apache Storm cluster
- C. Azure Stream Analytics
- D. HDInsight Apache Hadoop cluster using MapReduce
- E. HDInsight Spark cluster
Answer: B
Explanation:
Storm runs topologies instead of the Apache Hadoop MapReduce jobs that you might be familiar with. Storm topologies are composed of multiple components that are arranged in a directed acyclic graph (DAG). Data flows between the components in the graph. Each component consumes one or more data streams, and can optionally emit one or more streams.
Python can be used to develop Storm components. References:
https://docs.microsoft.com/en-us/azure/hdinsight/storm/apache-storm-overview
NEW QUESTION 20
A company has a SaaS solution that uses Azure SQL Database with elastic pools. The solution contains a dedicated database for each customer organization. Customer organizations have peak usage at different periods during the year.
You need to implement the Azure SQL Database elastic pool to minimize cost. Which option or options should you configure?
- A. Number of transactions only
- B. eDTUs per database only
- C. Number of databases only
- D. CPU usage only
- E. eDTUs and max data size
Answer: E
Explanation:
The best size for a pool depends on the aggregate resources needed for all databases in the pool. This involves determining the following: Maximum resources utilized by all databases in the pool (either maximum DTUs or maximum vCores depending on your choice of resourcing model). Maximum storage bytes utilized by all databases in the pool.
Note: Elastic pools enable the developer to purchase resources for a pool shared by multiple databases to accommodate unpredictable periods of usage by individual databases. You can configure resources for the pool based either on the DTU-based purchasing model or the vCore-based purchasing model.
References:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-elastic-pool
NEW QUESTION 21
You need to develop a pipeline for processing data. The pipeline must meet the following requirements.
•Scale up and down resources for cost reduction.
•Use an in-memory data processing engine to speed up ETL and machine learning operations.
•Use streaming capabilities.
•Provide the ability to code in SQL, Python, Scala, and R.
•Integrate workspace collaboration with Git. What should you use?
- A. HDInsight Spark Cluster
- B. Azure Stream Analytics
- C. HDInsight Hadoop Cluster
- D. Azure SQL Data Warehouse
Answer: B
NEW QUESTION 22
Note: This question is part of series of questions that present the same scenario. Each question in the series contain a unique solution. Determine whether the solution meets the stated goals.
You develop a data ingestion process that will import data to a Microsoft Azure SQL Data Warehouse. The data to be ingested resides in parquet files stored in an Azure Data Lake Gen 2 storage account.
You need to load the data from the Azure Data Lake Gen 2 storage account into the Azure SQL Data Warehouse.
Solution:
1. Use Azure Data Factory to convert the parquet files to CSV files
2. Create an external data source pointing to the Azure storage account
3. Create an external file format and external table using the external data source
4. Load the data using the INSERT…SELECT statement Does the solution meet the goal?
- A. Yes
- B. No
Answer: B
Explanation:
There is no need to convert the parquet files to CSV files.
You load the data using the CREATE TABLE AS SELECT statement. References:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-load-from-azure-data-lake-store
NEW QUESTION 23
......
P.S. DumpSolutions now are offering 100% pass ensure DP-200 dumps! All DP-200 exam questions have been updated with correct answers: https://www.dumpsolutions.com/DP-200-dumps/ (88 New Questions)